Moving data from multiple sources into multiple databases is one of the data engineer responsibilities. It is always recommended to use simple and direct approach first, especially when the data is small enough, like iterating data one by one and inserting it at the same time. However this approach will not going to work well on larger sized data or higher throughput stream data.
In this blog post, we will demonstrate how to insert JSON text file into Google’s BigQuery Table using Go language and its various native libraries (channel, goroutine, waitgroup). Go is known for one of the best language to write high-performance programs due to its native libraries that make concurrent and parallel programming easier.
Preparation
For preparation, let’s create a text file containing 1 million rows of single JSON per row, using a python script provided below[1].
# Generate dataset
python3 gen-txt.py
# you will see files like this
# -rw-rw-r-- 1 pandu pandu 220 Mar 5 18:31 students-10.json.txt
# -rw-rw-r-- 1 pandu pandu 2.3K Mar 5 18:31 students-100.json.txt
# -rw-rw-r-- 1 pandu pandu 24K Mar 5 18:31 students-1000.json.txt
# -rw-rw-r-- 1 pandu pandu 244K Mar 5 18:31 students-10000.json.txt
# -rw-rw-r-- 1 pandu pandu 2.5M Mar 5 18:31 students-100000.json.txt
# -rw-rw-r-- 1 pandu pandu 26M Mar 5 18:31 students-1000000.json.txt
We will get text files like this. In this case, each row contains 22 characters = 22 Bytes.
{"id":1,"name":"aaa"}
{"id":2,"name":"bbb"}
...
For BigQuery, make sure we have GCP key JSON file that has access to modify BigQuery table and don’t forget to export it to GOOGLE_APPLICATION_CREDENTIALS env var. After that, we all set.
Part One: Simple Approach
We will do three approaches to do insertion. But first, let’s use simplest approach. Read text file one by one and insert it to a BigQuery table one at a time.
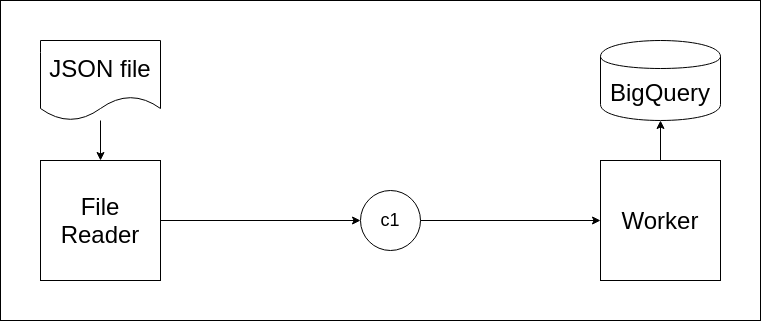
In this diagram, there are three main components: 1) File Reader, 2) Channel c1, and 3) Worker. File Reader is for reading text file and sending lines to channel c1. Channel c1 is for sharing string data. Worker is responsible for receiving string data from channel c1 and inserting it into a BigQuery table.
Channel is a native type in Go that enable us to send/receive values and share it across coroutine (goroutine). Let’s define Channel c1 first.
c1 = make(chan string)
Next, define File Reader as an anonymous function and immediately run it as a goroutine. Using go keyword in front of function call can enable it to run asynchronously/non-blocking to main function (goroutine).
// Read file line by line and send it to channel
log.Info("Reading file")
go func(filepath string, chanStr chan<- string) {
file, _ := os.Open(filepath)
defer file.Close()
scanner := bufio.NewScanner(file)
counter := 0
for scanner.Scan() {
text := scanner.Text()
chanStr <- text
counter++
}
close(chanStr)
log.Info("Finished reading ", counter, " rows")
}(FILEPATH, c1)
Next, define Worker outside main function. What this function does is to continuously receiving string data from a channel, parse it, and insert it to BQ Table. When the channel is closed, it will stop.
func deployWorker(ch <-chan string, project, dataset, table string, wg *sync.WaitGroup) {
// Create BQ client and context
client, ctx := getBQClient(project)
// Looping to receive data from channel
for {
strJSON, more := <-ch
if !more {
break
} else {
user := parseUserFromJSONStr(strJSON)
users := []*User{&user}
// Insert to BQ table
bqErr := insertUsersToBQTable(ctx, client, dataset, table, users)
if bqErr == nil {
log.Info(fmt.Sprintf("Inserted %d rows - %s", len(users), strJSON))
}
}
}
client.Close()
wg.Done()
}
Run it as a goroutine.
var wg sync.WaitGroup
wg.Add(1)
go deployWorker(c1, PROJECT, DATASET, TABLE, &wg)
wg.Wait()
log.Info("Done in ", time.Since(start).Seconds(), "seconds")
Don’t forget that goroutines are asynchronous, the program will done be immediately. To prevent that, Go has native feature called WaitGroup. It enables goroutine to be done first and then proceed to the next step. It is one of very important Go native features, WaitGroup usually used for waiting multiple parallel goroutines.
This Go script is available at cmd/main1/main1.go[1].
Part Two: Multiple Rows Insertion
According to BigQuery Streaming Insert Documentation[2], multiple rows can be inserted in one API call. Let’s modify our program.
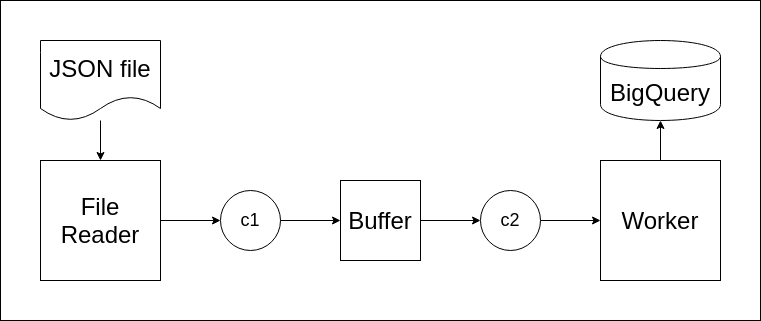
In this new architecture, we add two more components. First is Buffer and the second is channel c2. Buffer receives string data from c1, collect it temporarily into an array with length n, and then send it to c2 simultaneously. Let’s run it as a goroutine.
// Put string data to a buffer and send it to another channel
go func(chInput <-chan string, chOutput chan<- []string, n int) {
rows := []string{}
counter := 0
for {
row, more := <-chInput
if !more {
break
}
rows = append(rows, row)
counter++
if counter == n {
chOutput <- rows
rows = []string{}
counter = 0
}
}
close(chOutput)
}(c1, c2, BUFFER_LENGTH)
Channel c2 is a []string type channel. It only receive/send an array of string.
c1 = make(chan string)
c2 = make(chan []string)
Next, modify Worker to receive new type of channel c2.
func deployWorker(ch <-chan []string, project, dataset, table string, wg *sync.WaitGroup) {
// Create BQ client and context
client, ctx := getBQClient(project)
// Looping to receive data from channel
for {
strJSONs, more := <-ch
if !more {
break
} else {
// Parser also modified
users := []*User{}
for _, strJSON := range strJSONs {
user := parseUserFromJSONStr(strJSON)
users = append(users, &user)
}
// Insert to BQ table
bqErr := insertUsersToBQTable(ctx, client, dataset, table, users)
if bqErr == nil {
log.Info(fmt.Sprintf("Inserted %d rows - %s", len(users), strJSONs))
}
}
}
client.Close()
wg.Done()
}
Finally the second approach is done. Using right number of n, it can improve insertion speed significantly. This Go script is available at cmd/main2/main2.go[1].
Part Three: Multiple Workers and Multiple Rows Insertion
For the third and final approach, we will take advantage of Go’s goroutine. Go can spawn multiple goroutines in large number and significantly faster than other coroutine in other programming languages.
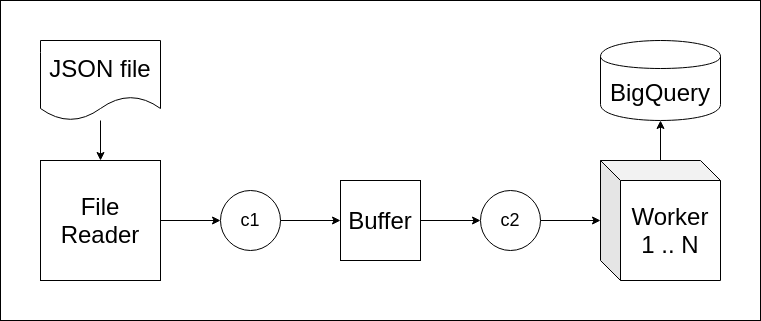
In this approach, we will simply deploy more workers using for loop. Let’s modify the main function a bit.
var wg sync.WaitGroup
for idx := 0; idx < WORKER_NUMBER; idx++ {
wg.Add(1)
go deployWorker(c2, PROJECT, DATASET, TABLE, &wg)
}
wg.Wait()
log.Info("Done in ", time.Since(start).Seconds(), "seconds")
In addition to n, another variable w is introduced. It determines how many workers should be deployed, and thus make insertion even faster. This Go script is available at cmd/main3/main3.go[1].
Benchmark
For deciding max number of buffer and workers, we need to read BigQuery Streaming API quotas and limits[3].
Maximum rows per request: 10,000 rows per request, maximum of 500 rows is recommended
Concurrent API requests, per user: 300
API requests per second, per user — 100
Benchmark was taken using same type of machine, n1-standard-1 (1 vCPU, 3.75 GB mem)[4]. Using multiple JSON text files generated at different sizes, we benchmark three approaches and measure time taken.
| File | Parameter | 1.000 rows | 10.000 | 100.000 | 1.000.000 |
|---|---|---|---|---|---|
| main.go | w1 - n1 | 312.164s | 3242.766s | n/a | n/a |
| main2.go | w1 - n100 | 4.599s | 35.735s | 381.251s | 3738.669s |
| main3.go | w4 - n100 | 1.453s | 9.137s | 95.666s | 939.175s |
| main3.go | w16 - n100 | 0.808s | 2.938s | 24.754s | 224.630s |
| main3.go | w64 - n100 | 0.848s | 1.643s | 11.667s | 62.624s |
| main3.go | w300 - n500 | 0.934s | 1.296s | 4.081s | 14.787s |
As we can see, higher number of w and n make insertion faster. Using our highest configuration enable us to insert one million rows in a mere 14 seconds!
Conclusion
In this blog post we learned to use concurrency/parallelism concept to make our programs do the job faster. We also explored Go language and its native libraries (channel, goroutines, waitgroup) to develop a high-performance program.
One thing to remember is that everything came with a tradeoff. We also need to watch out for memory and/or API calls limit when using large number of goroutines.
Also checkout my open source project ps2bq. It is a tool to insert GCP PubSub messages into BigQuery table. It was also developed using Go and concurrency/parallelism concept.
Leave a comment